Which Conclusion Can Be Made About a Sample When Using Only Pcr Technology to Detect Viruses?
Introduction
The phrase "Polymerase concatenation reaction" (PCR) was outset used more than thirty years ago in a newspaper describing a novel enzymatic distension of DNA (Saiki et al., 1985). The first applications of PCR were rather unpractical due to the usage of thermolabile Klenow fragment for amplification, which needed to be added to the reaction after each denaturation step. The crucial innovation which enabled routine usage of PCR was utilization of thermostable polymerase from Thermus aquaticus (Saiki et al., 1988). This improvement, together with the availability of PCR cyclers and chemical components, led to the worldwide recognition of PCR every bit the tool of choice for the specific enzymatic amplification of DNA in vitro. It must be noted that the general concept of PCR, which includes primers, DNA polymerase, nucleotides, specific ions, and Dna template, and consisting of cycles that comprise steps of DNA denaturation, primer annealing, and extension, accept not been changed since 1985. The invention of PCR has profoundly boosted research in various areas of biology and this technology has significantly contributed to the electric current level of homo knowledge in many spheres of research.
The most substantial milestone in PCR utilization was the introduction of the concept of monitoring Dna amplification in existent time through monitoring of fluorescence (Holland et al., 1991; Higuchi et al., 1992). In real time PCR (also denoted every bit quantitative PCR—qPCR; usage of RT-PCR is inappropriate as this abbreviation is defended to reverse transcription PCR), fluorescence is measured afterward each cycle and the intensity of the fluorescent signal reflects the momentary amount of DNA amplicons in the sample at that specific time. In initial cycles the fluorescence is too low to be distinguishable from the background. However, the point at which the fluorescence intensity increases above the detectable level corresponds proportionally to the initial number of template Dna molecules in the sample. This point is called the quantification wheel (Cq; different manufactures of qPCR instruments use their ain terminology, but since 2009, the term Cq is used exclusively) and allows determination of the absolute quantity of target DNA in the sample according to a calibration curve constructed of serially diluted standard samples (usually decimal dilutions) with known concentrations or copy numbers (Yang and Rothman, 2004; Kubista et al., 2006; Bustin et al., 2009).
Moreover, qPCR can likewise provide semi-quantitative results without standards just with controls used as a reference fabric. It this example, the observed results tin be expressed as college or lower multiples with reference to command. This awarding of qPCR has been extensively used for factor expressions studies (Bustin et al., 2009), only did non obtain the same success in microbiology quantification since it is unable to produce absolute quantitative values.
There are two strategies for the real time visualization of amplified DNA fragments—non-specific fluorescent Deoxyribonucleic acid dyes and fluorescently labeled oligonucleotide probes. These 2 approaches were developed in parallel (The netherlands et al., 1991; Higuchi et al., 1992) and are used in pathogen detection; however, probe-based chemistry prevails. This is due to its college specificity mediated by the additional oligonucleotide—the probe—and the lower susceptibility to visualize non-specific PCR products, eastward.k., primer dimers (Bustin, 2000; Kubista et al., 2006).
To fully empathise the possibilities of qPCR in detecting and quantifying target Deoxyribonucleic acid in samples it is essential to describe the mathematical principle of this method. The PCR is an exponential process where the number of Deoxyribonucleic acid molecules theoretically doubles after each cycle (if the efficiency of the reaction is 100%). More than more often than not, the amplification reaction follows this equation:
where Nn is the number of PCR amplicons after north cycles, Due north0 is the initial number of template copies in the sample, Due east is the PCR efficiency that can assume values in the range from 0 to 1 (0–100%) and n is number of cycles. In a scenario where in that location is initially one copy of the template in the reaction and PCR efficiency is 100%, information technology is possible to simplify the equation as follows:
If a calibration curve is run, ordinarily ten-fold serial dilutions are used. The difference in Cq values betwixt two 10-fold serial dilutions could be expressed as
Then due north = 3.322. When E should be determined the (i) is starting point and the equation is
If due north is taken to exist iii.322, and then E = one, i.e., 100%.
The PCR efficiency is therefore a significant gene for the quantification of the target DNA in unknown samples. The reliability of the scale bend in enabling quantification is then adamant by the spacing of the serial dilutions. If the Log10 of the concentration or re-create number of each standard is plotted against its Cq value (Figure 1), the E tin exist derived from the regression equation describing the linear function:
Where ten and y, the concentration/amount of target and Cq values respectively, characterize the coordinates in the plot, thousand is the regression coefficient or slope and c is the intercept. Taking the model regression equation from Figure one, the slope is −3.322, which mean that Eastward = 100% according to (4). The intercept shows the Cq value when ane copy would exist theoretically detected (Kubista et al., 2006; Johnson et al., 2013). The concentration or corporeality of target nucleic acid in unknown samples is so calculated according to the Cq value through Equation (five).
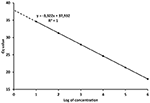
Figure 1. Model calibration curve with the regression equation (characterized by the slope and intercept) and regression coefficient.
From the definitions in a higher place it is evident that Cq values are instrumental readings, and must be recalculated to values with specific units, e.k., copies of organism, ng of Deoxyribonucleic acid, various concentrations, etc., (Bustin et al., 2009; Johnson et al., 2013). Notwithstanding, referral to Cq values in scientific papers is widespread and interpretations based on Cq values tin atomic number 82 to misleading conclusions. Concentrations in qPCR are expressed in the logarithmic calibration (Figure 1) and Cq differences between x-fold serial dilutions are theoretically ever 3.322 cycles. Therefore, although the numerical difference between Cq 20 and 35 is rather negligible, the difference in existent numbers (copies, ng) is virtually five orders of magnitude (Log10).
This feature must be reflected in the subsequent calculations. For example, the coefficient of variation (CV, ratio between standard deviation and mean) calculated from the Cq values and real numbers results in profoundly unlike results. The same applies for any statistical tests where Cq values are used, fifty-fifty for cases where the logarithm of Cq values is used for the normalization of data before the statistical evaluation. The correct procedure should include initial recalculation to existent numbers followed by logarithmic transformation.
Pros and Cons of Using qPCR in Detection and Quantification of Pathogens
Since PCR is capable of amplifying a specific fragment of DNA, information technology has been used in pathogen diagnostics. With the increasing amount of sequencing data available, information technology is literally possible to design qPCR assays for every microorganism (groups and subgroups of microorganisms, etc.) of interest. The primary advantages of qPCR are that information technology provides fast and high-throughput detection and quantification of target DNA sequences in unlike matrices. The lower fourth dimension of amplification is facilitated past the simultaneous amplification and visualization of newly formed Deoxyribonucleic acid amplicons. Moreover, qPCR is safer in terms of avoiding cross contaminations because no further manipulation with samples is required afterwards the amplification. Other advantages of qPCR include a wide dynamic range for quantification (seven–viii Log10) and the multiplexing of amplification of several targets into a single reaction (Klein, 2002). The multiplexing choice is essential for detection and quantification in diagnostic qPCR assays that rely on the inclusion of internal distension controls (Yang and Rothman, 2004; Kubista et al., 2006; Bustin et al., 2009).
qPCR assays are used not but for the detection, just besides to determine the presence of specific genes and alleles, due east.one thousand., typing of strains and isolates, antimicrobial resistance profiling, toxin production, etc., However, the mere presence of genes responsible for resistance to antimicrobial compounds or fungal toxin product does not automatically mean their expression or product. Therefore, although qPCR-based typing tests are faster, their results should be correlated with phenotypic and biochemical tests (Levin, 2012; Osei Sekyere et al., 2015).
Equally for the microbial diagnostics, there are different considerations in detecting and quantifying viral, bacterial, and parasitic agents. These considerations are based on the target (Deoxyribonucleic acid or RNA), cultivability, interpretation of results, and clinical significance of qPCR results.
qPCR plays an important office in the detection, quantification, and typing of viral pathogens. This is because detection of of import clinical and veterinary viruses using culture methods is fourth dimension-consuming or impossible, while ELISA tests are non universally bachelor and suffer from comparatively low sensitivity and specificity. qPCR (with the inclusion of reverse transcription for the diagnostics of RNA viruses) provides the appropriate sensitivity and specificity (Hoffmann et al., 2009). Moreover, determination of the viral load by (RT)-qPCR is used as an indicator of the response to antiviral therapies (Watzinger et al., 2006). For these reasons (RT)-qPCR has become an indispensable tool in virus diagnostics (Yang and Rothman, 2004).
The situation is similar in the case of intestinal protozoan diagnostics (Rijsman et al., 2016). The gold standard technique for the detection of protozoan agents, the microscopic test of feces, is laborious, fourth dimension-consuming, and requires specifically trained personnel. Similarly, ELISA testing suffers from depression sensitivity and specificity (Rijsman et al., 2016). Therefore, qPCR is now emerging as a powerful tool in the routine detection, quantification, and typing of abdominal parasitic protozoa.
In contrast to viral and protozoan detection and quantification, many bacteria of clinical, veterinary, and food safety significance, tin can be cultured. For this reason, culture is considered as the gold standard in bacterial detection and quantification. However, in cases when disquisitional and timely intervention for infectious disease is required, the traditional, slow, and multistep civilisation techniques cannot provide results in a reasonable time. This limitation is compounded by the necessity of culturing fastidious pathogens and additional testing (species determination, identification of virulence factors, and antimicrobial resistance). qPCR is capable of providing the required information in a brusk time; however, the phenotypic and biochemical features must be confirmed from bacterial isolates (Yang and Rothman, 2004).
In food safety, all international standards for food quality rely on the conclusion of pathogenic microorganisms using traditional civilization methods. qPCR techniques stand for an fantabulous culling to existing standard civilization methods equally they enable reliable detection and quantification (for several pathogens) and harbor many other advantages equally discussed above. Still, there are limitations with respect to the sensitivity of assays based on qPCR. Every bit culture methods rely on the multiplication of bacteria during the pre-culture steps (pre-enrichment), samples for DNA isolation usually initially incorporate very depression numbers of target bacteria (Rodriguez-Lazaro et al., 2013). This limitation leads to the most important disadvantage of qPCR, which is its inherent incapability of distinguishing between live and expressionless cells. The usage of qPCR itself is therefore express to the typing of bacterial strains, identification of antimicrobial resistance, detection, and possibly quantification in not-processed and raw food. It is of import to note that candy food can still contain amplifiable DNA even if all the potentially pathogenic bacteria in food are devitalized and the foodstuff is microbiologically safe for consumption (Rodriguez-Lazaro et al., 2013). To overcome this problem, a pre-enrichment of sample in civilization media could exist placed prior to the qPCR. This step may include non-selective enrichment in buffered peptone water or specific selective media for the corresponding bacterium. This procedure is primarily intended to permit resuscitation/recovery and subsequent multiplication of the bacteria for the downstream qPCR detection; the second advantage is dilution and emptying of possible PCR inhibitors present into the sample (presence of salts, conservation substances, etc.). The extraction of the DNA from the culture media is easier than that from the food samples, which are much more heterogeneous in terms of composition (Margot et al., 2015).
Although qPCR itself cannot distinguish amidst viable and expressionless cells attempts take been made to adapt qPCR for viability detection. It was shown that RNA has low stability and should be degraded in dead cells inside minutes. However, the correlation of jail cell viability with the persistence of nucleic acid species must be well characterized for a detail state of affairs before an appropriate distension-based analytical method can be adopted as a surrogate for more traditional civilization techniques (Birch et al., 2001). Moreover, difficulties connected with RNA isolation from samples like food, feces or ecology samples tin provide false-negative results especially when low numbers of target cells are expected.
Another option for conclusion of viability using qPCR is the deployment of intercalating fluorescent dyes like propidium monoazide (PMA) and ethidium monoazide (EMA; Nocker and Camper, 2009). In these methods, the criterion for viability determination is membrane integrity. Metabolically agile cells (regardless of their cultivability) with total membrane integrity keep the dyes exterior the cells and are therefore considered as viable. However, if plasma membrane integrity is compromised, the dyes penetrate the cells, or react with the DNA outside of dead cells. The labeled Dna is then not available for the distension past qPCR and the difference between treated and untreated cells provides information almost the proportion of viable cells in the sample. The limitation of this method is the necessity to have the cells in a light-transparent matrix, e.g., water samples, cell cultures, etc., every bit the intercalation of the dye to Dna requires exposure to light. Therefore, samples of insufficient light transparency practice not permit the application of these dyes. There is a preference for PMA over EMA, equally it was shown that EMA penetrates the membranes of live bacterial cells (Nocker et al., 2006).
Moreover, some other topic nosotros want to but to mention here is the generation and use of standards required for the scale curves. In full general, two are the most diffused approaches for the generation of calibration curves. One employs dilutions of target genomic nucleic acrid and the other plasmid standards. Both strategies can lead to a concluding quantification of the target, simply plasmids containing specific target sequences offer the advantages of like shooting fish in a barrel production, stability, and cheapness. On the other paw, in principle, PCR efficiency obtained by plasmid standards sometimes could differ compared to the efficiency obtained using genomic standard, which instead, for organisms captious to growth, could be isolated but starting from a given matrix, and thus susceptible to degradation and losses (Chaouachi et al., 2013). Finally, the production and validation of international quantification standards for qPCR assays is technically enervating and these standards are currently available only for a few targets (Pavšič et al., 2015).
qPCR Parameters in Microbial Detection and Quantification
Analytical Specificity (Selectivity)
This parameter in qPCR refers to the specificity of primers for target of interest. Analytical specificity consists of two concepts: inclusivity describes the ability of the method to detect a broad range of targets with defined relatedness eastward.grand., taxonomic, immunological, genetic composition (Anonymous, 2009, 2015a). Some other definition describes inclusivity as the strains or isolates of the target analyte(s) that the method can observe (Anonymous, 2012). ISO 16140 and other standards recommend that inclusivity should be determined on 20–l well-defined (certified) strains of the target organism (Anonymous, 2009, 2011, 2012, 2015a; Broeders et al., 2014), or for Salmonella, it is recommended that 100 serovars should exist included for inclusivity testing (Anonymous, 2012).
On the other hand, exclusivity describes the power of the method to distinguish the target from similar but genetically distinct non-targets. In other words, exclusivity can likewise exist divers as the lack of interference from a relevant range of non-target strains, which are potentially cantankerous-reactive (Bearding, 2009, 2011, 2012, 2015a). The desirable number of positive samples in exclusivity testing is zero (Johnson et al., 2013).
Belittling Sensitivity (Limit of Detection, LOD)
Many official documents have discussed theories and procedures for the correct definition of the LOD for different methods. A general consensus was reached around the definition of the LOD as the lowest corporeality of analyte, which can be detected with more than than a stated percentage of confidence, but, not necessarily quantified every bit an exact value (Anonymous, 2011, 2013, 2014). In this regard, the confidence level obtained or requested for the definition of LOD can reflect the number of replicates (both technical and experimental) needed by the assay in society to reach the requested level of confidence (due east.g., 95%). It is clear that the more than replicates are tested, the narrower will exist the interval of confidence. Another definition describes the LOD as the lowest concentration level that tin can be adamant equally statistically unlike from a blank at a specified level of confidence. This value should be determined from the analysis of sample blanks and samples at levels most the expected LOD (Anonymous, 2015a). However, it should be noted that LOD definitions described above were reported for chemical methods, and are not perfectly suited for PCR methods (Burns and Valdivia, 2008). This is because, for limited concentrations of analyte (nucleic acids), the output of the reaction can be a success (distension), or a failure (no distension at all), without any blank, or critical level at which it is possible to ready a cut-off value over which the sample can be considered as positive one. Moreover, information technology should exist remembered hither that, by definition, a bare sample should never be positive in PCR.
Since the definitions reported above are not practicable for PCRs, other approaches have been proposed. A conservative approach is to consider the LOD value every bit the minimum concentration of nucleic acid or number of cells, which always gives a positive PCR event in all replicates tested, or in the major part (over 95%) of them (Nutz et al., 2011). In practice, multiple aliquots of a specific matrix are spiked with series dilutions of the target organism and undergo the whole process of nucleic acrid isolation and qPCR. The LOD is then divers as the spike amount of target organism in dilution that could be detected in 95% of replicates. For instance, 10 replicates of milk samples were spiked with serial dilutions of Campylobacter jejuni in amounts of 10five–100 cells per 1 ml of milk. The experimentally adamant LOD of the method for the detection of C. jejuni in milk is approximately i.56 × 103 cells/ml of milk (Figure 2). In guild to better define the well-nigh precise value, more than dilutions can be tested before reaching a final LOD value every bit shut every bit possible to the real one. The number of replicates tested should be at least six (Slana et al., 2008; Kralik et al., 2011); even so, the more replicates (x or 15 and more; Ricchi et al., 2016) performed, the college level of confidence of the LOD that can exist achieved (Anonymous, 2015b).
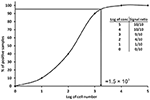
Effigy 2. Graphical representation of the decision of limit of detection (LOD) in qPCR. The data in the table show the number of positive samples/all analyzed samples (signal ratio).
According to the Poisson distribution, it was concluded that the LOD for PCR cannot be lower than at to the lowest degree iii copies of the nucleic acid targets (Bustin et al., 2009; Johnson et al., 2013). However, this value refers to the theoretical LOD of the qPCR methodology, which is capable of detecting a single target DNA molecule in the sample. Assuming this, such LOD for all optimized qPCR assays will exist similar. Therefore, as stated in a higher place, the LOD must be related to the whole method that includes nucleic acid training and qPCR. Only under these conditions tin information technology stand for a valid parameter that describes the features of the corresponding qPCR method (Bearding, 2015a).
However, sometimes it is not possible to obtain big numbers of replicates, for both financial and technical reasons. To overcome these problems, an increasing number of reports apply Probit or Logit approaches for determining the LOD for PCR methods (Burns and Valdivia, 2008; Anonymous, 2014; Pavšic et al., 2016; Ricchi et al., 2016). Briefly, both mathematical functions are regressions used to analyse binomial response variables (positive or negative) and are able to transform the sigmoid dose-response curve, typical of a binomial variable, to a straight line that can then exist analyzed by regression either through to the lowest degree squares or maximum likelihood methods. The terminal end-point of the analysis is a concentration (coupled with relative intervals of confidence), associated to a probability (e.g., 95%) to find the nucleic acid. Moreover, Probit regression is exploitable only for ordinarily distributed information, while Logit part can also be used for data not normally distributed; however, in this context, both functions accept the aforementioned significant.
Finally, it must be noted that LOD is not a limiting value and therefore, that Cq values below the LOD cannot automatically be considered as negative. From the definition of LOD, information technology is axiomatic that values beneath the LOD are absolutely valid in terms of microorganism presence; nonetheless, the probability of their repeated detection is lower than 95%. This feature is connected with the Poisson distribution when working with pocket-sized numbers.
Limit of Quantification (LOQ)
The documents already cited for the LOD definitions besides comprise analog definitions for the LOQ. The LOQ was divers equally the smallest corporeality of analyte, which tin exist measured and quantified with defined precision and accuracy under the experimental conditions by the method under validation (Armbruster and Pry, 2008; Bearding, 2011, 2013). An alternative definition is that the LOQ is the everyman corporeality or concentration of analyte that tin be quantitatively determined with an adequate level of dubiety (Bearding, 2015a). It is clear that, according to the previous definitions, the LOQ can never be lower than the LOD.
In practice, the LOQ is determined as is the LOD, on replicates of spiked samples, just the assessment of results is quantitative. Numerically, the LOQ is defined every bit the everyman concentration of analyte, which gives a predefined variability, mostly reported every bit the coefficient of variation (CV). For qPCR, this value has been proposed to exist stock-still nether 25% (Broeders et al., 2014; Dreo et al., 2014; Bearding, 2015b; Pavšic et al., 2016), begetting in mind that the Cq values must be recalculated to copies or g of nucleic acids earlier performing the evaluation of the CV (Bustin et al., 2009; Johnson et al., 2013). Hoverer, this value was proposed based on the experience accrued in GMO detection laboratories (Broeders et al., 2014; Anonymous, 2015b), and at that place is no general understanding regarding any technical standards for molecular methods in microbiology. Therefore, we propose here to define the LOQ in the molecular diagnosis of microorganisms as the lowest concentration, amount, or number of analytes with a CV < 25%.
Another arroyo for the determination of the LOQ of qPCR is based on the use of the Youden alphabetize (J) and receiver operating characteristic curves (Nutz et al., 2011). This last index was defined equally J = sensitivity + specificity −1 (Fluss et al., 2005). A series of spiked samples with different concentrations of target DNA were analyzed and the J-values were calculated for each PCR cycle. The LOQ was then fixed as the concentrations of DNA where the J-values were highest (Nutz et al., 2011).
Finally, an consequence that should be addressed for the determination of the LOQ too as LOD is the efficiency of recovery of target molecules during the nucleic acid extraction phases. Generally, nucleic acids are extracted from different circuitous matrices, like nutrient, feces, or other samples using different procedures. The efficiency of Deoxyribonucleic acid recovery is ordinarily around 30% and lower (Slana et al., 2008; Kralik et al., 2011; Ricchi et al., 2016) and neglecting this parameter leads to underestimation of the true number of target microorganisms in the original sample, which is and then reflected past the lower LOD and LOQ values. Therefore, determination of Dna isolation efficiency should be part of the LOD and LOQ. DNA isolation efficiency is a quotient between the number of microorganisms recovered after the entire process (nucleic acid extraction + qPCR) and the number of microorganisms used for spiking the negative matrices (Slana et al., 2008; Kralik et al., 2011; Ricchi et al., 2016). Due to the fact that these data are provided during the determination of the LOD and LOQ, information technology is not necessary to perform additional experiments. Information technology is recommended that the median of hateful DNA isolation values from unlike dilutions is used as the practical overall Deoxyribonucleic acid isolation efficiency (Kralik et al., 2011).
Similarly to the LOD, quantity tin also be assessed in samples with numbers of organisms or concentrations of DNA lower than the LOQ, only the conviction of such quantification will be lower than that alleged by the definition of LOQ. Moreover, in that location are possibilities of how to refer to such quantities in terms of semi-quantitative interpretation, e.g., range of values (ten2–101 cells/g).
Amplification Efficiency of qPCR (E)
This parameter was mentioned above in the section defended to the mathematical description of qPCR (Equation 4). PCR efficiency should exist in the range of 0–one (0–100%); when Due east = 1 this means that the number of newly formed Deoxyribonucleic acid amplicons is doubled in each cycle. This is difficult to accomplish repeatedly over time. In practice, this parameter is likely to be in the range 90–105% (Johnson et al., 2013). This parameter can be estimated from the gradient of the calibration curve.
In connection to this issue, the everyman and highest concentrations of the standard included in the calibration curve, which tin exist truly quantified, should be determined co-ordinate to the linear dynamic range of over at least half dozen Logx. The dynamic range is divers past the MIQE guidelines as the range over which a reaction is linear (Bustin et al., 2009).
The determination of PCR efficiency past the standard curve really provides two pieces of data. If an inhibitor would be present in the most full-bodied sample, there would be a visible increment in Cq values in these and therefore a diminishment of the 3.322 Cq span at higher concentrations. However, this is not a frequent miracle, equally standards are normally well-characterized and therefore, any inhibition is rather unlikely. If there would be a similar state of affairs in lower concentration samples, this suggests a possible pipetting error rather than the presence of inhibitors. An important function to assess this is the coefficient of conclusion (R 2 value), that should be college than 0.98 (Johnson et al., 2013). In reality, it is much more than important to determine the PCR inhibition and subsequent diminishment of the PCR efficiency in analyzed samples. There are approaches based on the assay of the fluorescent bend of each sample past specific software (LinRegPCR), which can calculate the PCR efficiency of each sample without the series of dilutions. However, this approach is not flawless equally it does non take into account all possible variables that can affect the assay (Ruijter et al., 2009).
Accuracy of PCR
The following parameters of qPCR deal with ways of how to compare novel qPCR methods with reference methods or materials. Accuracy is defined as a measure of the degree of conformity of a value generated by a specific process to the assumed or accepted true value (Anonymous, 2015a). In other words, accuracy describes the level of understanding betwixt reference and measured values. In that location are several aspects that need to be considered in terms of defining accuracy. In binary classification tests (qualitative detection), the samples analyzed by a novel (alternative) test that needs to be verified (typically a novel qPCR analysis) are categorized according to their cyclopedia with the reference method in iv basic categories (Table i). This segmentation originates from the statistical nomenclature known as error matrix and allows conclusion of several parameters that depict the diagnostic potential of the qPCR method.

Table 1. Parameters for comparing of qPCR results with a reference method in a 2 × 2 error matrix contingency tabular array.
Diagnostic sensitivity, which is described equally TP/(TP + FN), refers to the ability of the new exam to correctly place samples identified past the reference method equally positive. The lower the diagnostic sensitivity, the poorer will be the inclusivity of the tested qPCR. Some other explanation could exist that the analytical sensitivity (LOD) of the reference method is college than the tested qPCR.
Diagnostic specificity is divers as the TN/(TN + FP) and refers to the ability of the test to correctly place samples that were found to be negative by the reference method. The lower the diagnostic specificity, the poorer will exist the exclusivity of the tested qPCR. Another explanation could be that the sensitivity of the reference method is quite bad, and the new qPCR method is capable of identifying more positive samples than the reference method.
Relative accuracy is defined as the (TP + TN)/(TP + TN + FP + FN) and describes the proportion of all correctly identified samples among all samples (Bearding, 2009). If no FN and FP are detected, then it is 100%. In all other cases, this value is lower than 100%.
In quantitative conclusion, the accurateness numerically describes the distance of the value from the novel tested qPCR and some reference (truthful) value. For this reason, accuracy is referred to every bit trueness in quantitative classification (Anonymous, 1994). Trueness is defined equally the caste of agreement of the expected value with the true value or accepted reference value. This is related to systematic error (Anonymous, 2015a,b). In GMO testing the trueness must be within 25% of the accepted reference value (Anonymous, 2015b). There are no stock-still values of trueness that the novel tested qPCR method must meet in microbiological diagnostics. This might exist caused by the fact that the trueness in qPCR can be determined by the comparison with some certified reference textile, with the reference method or by proficiency testing. Certified reference material with a quantified number of target organisms is available just for a express number of organisms (specially viruses like HIV, HBV, HCV, HAV, HPV, CMV, EBV), while for the remainder of clinically pregnant organisms, these materials are often available but for the qualitative assay, and are therefore non suitable for trueness determination. Reference methods normally have varying diagnostic sensitivities and specificities and often they do not fit for the purposes of the quantitative assessment of novel qPCR methods. Moreover, the organization of proficiency testing via band trials is expensive and requires a supplier of the reference textile (like QCMD). These are the principal reasons why determination of trueness in qPCR methods for the microbial detection in clinical, and especially in veterinary food safety areas, is rather express.
Precision of qPCR
Precision is defined as the degree of agreement of measurements under specified atmospheric condition. The precision is described past statistical methods such as SD or conviction limit (Anonymous, 2015a). From the definition of precision, it is evident that this qPCR parameter is quantitative. For practical determination of precision, two conditions termed repeatability, and reproducibility were introduced (Anonymous, 1994). These ii parameters are used to draw the variability of measurements introduced by the operator, equipment, and its scale, ecology factors that tin can influence the measurement like temperature, humidity etc., and time between measurements (Anonymous, 1994). Repeatability is described as the closeness of agreement between successive and independent results obtained by the same method on identical test material under the same conditions (apparatus, operator, laboratory, and brusque intervals of time) and expresses within-laboratory variations (Bearding, 1994, 2009, 2015a). Repeatability consists of 2 different variables: intra- and inter-assay variation. The intra-assay variation describes the variability of the replicates conducted in the same experiment; the inter-assay variation describes the variability between different experiments conducted on dissimilar days. Numerically, the repeatability is characterized equally the SD of replicates at each concentration of each matrix for each method (Anonymous, 2012). The interval characterized past the SD of the replicates is called the repeatability limit (r) and is defined as the value less than or equal to the expected accented difference, with a probability of 95%, between two tests results obtained nether repeatability weather condition (Anonymous, 1994, 2009, 2015b; Broeders et al., 2014). If the measured value lies outside the SD, it should be considered as doubtable (Bearding, 2009). Information technology is necessary to perform the interpretation of repeatability on 15 repeats at least (Anonymous, 1994, 2015b). Testing of repeatability requires analysis of the spiked relevant matrix at least at four levels—loftier, medium, low (nigh to the LOD) and negative in at to the lowest degree duplicates (Bearding, 2009). For more than rigorous testing the utilize of 5 replicates and the addition of one more sample spiked with a competitor strain that gives similar results in the given detection system is recommended. Natural background microflora can fulfill this requirement as long as they are present in the matrix at a level 1 Log10 greater than the target analyte (Anonymous, 2015a). In clinical, veterinary and food microbial detection, at that place are no specific recommendations for the repeatability SD value in terms of its proportion with respect to the mean. In GMO detection the repeatability SD must exist ≤25% established on samples containing 0.1% GM related to the mass fraction of GM fabric (Broeders et al., 2014; Anonymous, 2015b).
On the other mitt, reproducibility is the closeness of agreement betwixt single test results on identical test fabric using the same method, obtained in different laboratories using different equipment and expresses the variation between laboratories (Bearding, 1994, 2009, 2015a). Numerically, the reproducibility is characterized as the SD replicates at each concentration for each matrix across all laboratories (Anonymous, 2012). Similarly to repeatability, the reproducibility limit (R), as the interval characterized by the SD of the replicates, is defined as a value less than or equal to which the accented departure betwixt ii examination results obtained nether reproducibility weather condition is expected to take a probability of 95% (Anonymous, 1994, 2009, 2015b). If the departure between two results from dissimilar laboratories exceeds R, the results must be considered suspect (Anonymous, 2009). The reproducibility is usually defined past collaborative studies, which determine the variability of the results obtained by the given method in different laboratories using identical samples (Anonymous, 2009, 2012; Molenaar-de Backer et al., 2016). The number of laboratories with valid results which should be included in the collaborative study is at to the lowest degree viii. Therefore, it is appropriate to select ten–12 labs (Anonymous, 2009, 2015a). The requirements for the minimal number of testing samples are identical to the repeatability decision (Anonymous, 2009, 2015a). Similarly, there are no specific recommendations for SD values of reproducibility with regard to the mean in clinical, veterinary, and nutrient microbial detection. Again, in GMO testing the SD of reproducibility should be <35% over the whole dynamic range. However, at relative concentrations <0.2% or at an corporeality <100 copies SD values <50% are accounted acceptable (Broeders et al., 2014; Anonymous, 2015b).
Although decision of qPCR precision requires quantitative data, there is also the possibility of determining the precision of the method qualitatively. The mechanism of precision determination remains identical equally for the quantitative estimation, including the validation within collaborative studies. However, the results are evaluated only qualitatively (positive/negative). This approach can be used for the validation of the specific new qPCR method in dissimilar laboratories, only it is preferably used for the validation and routine control of diverse qPCR methods in different laboratories on a set of reference samples. Such samples are provided past certain authorities (reference laboratories) or private companies (QCMD), which collect data from dissimilar laboratories and in the example of success, provide certificates regarding participation in such testing.
Conclusion
qPCR technology represents a powerful tool in microbial diagnostics. In viral and parasitical detection, quantification and typing, the suitability of this technique is across dubiety; in the expanse of bacterial diagnostics it can supplant culture techniques, especially when rapid and sensitive diagnostic assays are required. The spread of qPCR to different areas of routine microbial diagnostics together with the lack of standard procedures for the decision of basic functional parameters of qPCR has led to a scenario in which standardization of methods is performed according to different rules past unlike laboratories. This issue was partially solved by the publication of MIQE guidelines (Bustin et al., 2009); however, there are differences in attitude to validation and standardization of qPCR assays across clinical, veterinary and food safety areas. Whatsoever contribution to the unification of standardization and validation procedures will improve the quality of qPCR assays in microbial detection, quantification and typing.
Author Contributions
Both authors listed, take made substantial, direct and intellectual contribution to the piece of work, and canonical it for publication.
Funding
The piece of work was supported by the MA CR RO0516 and MEYS CR NPU I program (LO1218). The funder had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Conflict of Interest Statement
The authors declare that the enquiry was conducted in the absenteeism of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors would like to thank Neysan Donnelly (Max-Planck-Institute of Biochemistry, Germany) for grammatical corrections of the manuscript.
References
Anonymous (1994). ISO 5725-1 - Accuracy (Trueness and Precision) of Measurement Methods and Results — Part 1: General Principles and Definitions. Geneva: ISO - International Organization for Standardization.
Anonymous (2009). Protocol for the Validation of Alternative Microbiological Methods. Søborg: NordVal International /Nordic Commission on Food Assay, NMKL.
Anonymous (2011). ISO 16140 - Microbiology of Food and Brute Feeding Stuffs - Protocol for the Validation of Alternative Methods. Geneva: ISO - International Organisation for Standardization.
Anonymous (2012). Methods Committee Guidelines for Validation of Microbiological Methods for Food and Environmental Surfaces. Rockville, MD: AOAC INTERNATIONAL.
Anonymous, R. (2013). Terrestrial Manual, seventh Edn, Affiliate i.1.5. Principles and Methods of Validation of Diagnostic Assays for Infectious Diseases (Version adopted in May, 2013). Paris: World Organisation for Animal Wellness.
Google Scholar
Bearding, R. (2014). OIE Validation Guidelines, 3.vi.5. Statistical Approaches To Validation. Paris: Globe Organisation for Animal Health.
Google Scholar
Anonymous, R. (2015a). Guidelines for the Validation of Analytical Methods for the Detection of Microbial Pathogens in Foods and Feeds, 2nd Edn. Silver Spring, Physician: US Nutrient & Drug Administration; Function of Foods and Veterinary Medicine.
Google Scholar
Anonymous, R. (2015b). JRC Technical Study - Definition of Minimum Performance Requirements for Analytical Methods of GMO Testing. Ispra: European Committee, Joint Research Centre; Institute for Health and Consumer Protection.
Google Scholar
Armbruster, D. A., and Pry, T. (2008). Limit of blank, limit of detection and limit of quantitation. Clin. Biochem. Rev. 29(Suppl. ane), S49–S52.
PubMed Abstract | Google Scholar
Birch, L., Dawson, C. Eastward., Cornett, J. H., and Keer, J. T. (2001). A comparing of nucleic acid amplification techniques for the assessment of bacterial viability. Lett. Appl. Microbiol. 33, 296–301. doi: 10.1046/j.1472-765X.2001.00999.xc
PubMed Abstract | CrossRef Full Text | Google Scholar
Broeders, S., Huber, I., Grohmann, Fifty., Berben, G., Taverniers, I., Mazzara, Grand., et al. (2014). Guidelines for validation of qualitative real-time PCR methods. Trends Food Sci. Technol. 37, 115–126. doi: x.1016/j.tifs.2014.03.008
CrossRef Full Text | Google Scholar
Burns, M., and Valdivia, H. (2008). Modelling the limit of detection in real-time quantitative PCR. Eur. Food Res. Technol. 226, 1513–1524. doi: 10.1007/s00217-007-0683-z
CrossRef Full Text | Google Scholar
Bustin, South. A. (2000). Absolute quantification of mRNA using real-time reverse transcription polymerase chain reaction assays. J. Mol. Endocrinol. 25, 169–193. doi: 10.1677/jme.0.0250169
PubMed Abstract | CrossRef Full Text | Google Scholar
Bustin, Southward. A., Benes, V., Garson, J. A., Hellemans, J., Huggett, J., Kubista, M., et al. (2009). The MIQE guidelines: minimum data for publication of quantitative real-time PCR experiments. Clin. Chem. 55, 611–622. doi: 10.1373/clinchem.2008.112797
PubMed Abstract | CrossRef Full Text | Google Scholar
Chaouachi, K., Bérard, A., and Saïd, Chiliad. (2013). Relative quantification in seed GMO assay: state of art and bottlenecks. Transgenic Res. 22, 461–476. doi: 10.1007/s11248-012-9684-1
PubMed Abstract | CrossRef Full Text | Google Scholar
Dreo, T., Pirc, M., Ramšak, Ž., Pavšic, J., Milavec, Yard., Zel, J., et al. (2014). Optimising droplet digital PCR assay approaches for detection and quantification of bacteria: a case study of fire blight and potato brown rot. Anal. Bioanal. Chem. 406, 6513–6528. doi: ten.1007/s00216-014-8084-1
PubMed Abstract | CrossRef Full Text | Google Scholar
Higuchi, R., Dollinger, G., Walsh, P. S., and Griffith, R. (1992). Simultaneous amplification and detection of specific Deoxyribonucleic acid sequences. Biotechnology 10, 413–417.
PubMed Abstract | Google Scholar
Hoffmann, B., Beer, 1000., Reid, S. M., Mertens, P., Oura, C. A., van Rijn, P. A., et al. (2009). A review of RT-PCR technologies used in veterinarian virology and disease control: sensitive and specific diagnosis of five livestock diseases notifiable to the World Organisation for Animate being Health. Vet. Microbiol. 139, 1–23. doi: 10.1016/j.vetmic.2009.04.034
PubMed Abstract | CrossRef Full Text | Google Scholar
Kingdom of the netherlands, P. M., Abramson, R. D., Watson, R., and Gelfand, D. H. (1991). Detection of specific polymerase concatenation reaction product by utilizing the 5′—3′ exonuclease activeness of Thermus aquaticus DNA polymerase. Proc. Natl. Acad. Sci. U.s.A. 88, 7276–7280.
PubMed Abstract | Google Scholar
Kralik, P., Slana, I., Kralova, A., Babak, V., Whitlock, R. H., and Pavlik, I. (2011). Development of a predictive model for detection of Mycobacterium avium subsp. paratuberculosis in faeces past quantitative real fourth dimension PCR. Vet. Microbiol. 149, 133–138. doi: 10.1016/j.vetmic.2010.10.009
PubMed Abstract | CrossRef Total Text | Google Scholar
Kubista, One thousand., Andrade, J. G., Bengtsson, M., Forootan, A., Jonak, J., Lind, K., et al. (2006). The real-time polymerase chain reaction. Mol. Aspects Med. 27, 95–125. doi: 10.1016/j.mam.2005.12.007
PubMed Abstract | CrossRef Full Text | Google Scholar
Margot, H., Zwietering, M. H., Joosten, H., O'Mahony, E., and Stephan, R. (2015). Evaluation of different buffered peptone h2o (BPW) based enrichment broths for detection of Gram-negative foodborne pathogens from various food matrices. Int. J. Nutrient Microbiol. 214, 109–115. doi: ten.1016/j.ijfoodmicro.2015.07.033
PubMed Abstruse | CrossRef Total Text | Google Scholar
Molenaar-de Backer, 1000. W., de Waal, Thou., Sjerps, M. C., and Koppelman, M. H. (2016). Validation of new real-time polymerase chain reaction assays for detection of hepatitis A virus RNA and parvovirus B19 Deoxyribonucleic acid. Transfusion 56, 440–448. doi: x.1111/trf.13334
PubMed Abstract | CrossRef Total Text | Google Scholar
Nocker, A., and Camper, A. Grand. (2009). Novel approaches toward preferential detection of feasible cells using nucleic acid amplification techniques. FEMS Microbiol. Lett. 291, 137–142. doi: 10.1111/j.1574-6968.2008.01429.x
PubMed Abstract | CrossRef Full Text | Google Scholar
Nocker, A., Cheung, C. Y., and Camper, A. K. (2006). Comparison of propidium monoazide with ethidium monoazide for differentiation of live vs. dead bacteria by selective removal of Dna from dead cells. J. Microbiol. Methods 67, 310–320. doi: 10.1016/j.mimet.2006.04.015
PubMed Abstract | CrossRef Full Text | Google Scholar
Nutz, Due south., Döll, K., and Karlovsky, P. (2011). Decision of the LOQ in existent-fourth dimension PCR by receiver operating characteristic curve analysis: application to qPCR assays for Fusarium verticillioides and F. proliferatum. Anal. Bioanal. Chem. 401, 717–726. doi: 10.1007/s00216-011-5089-x
PubMed Abstract | CrossRef Full Text | Google Scholar
Osei Sekyere, J., Govinden, U., and Essack, Due south. Y. (2015). Review of established and innovative detection methods for carbapenemase-producing Gram-negative bacteria. J. Appl. Microbiol. 119, 1219–1233. doi: 10.1111/jam.12918
PubMed Abstract | CrossRef Total Text | Google Scholar
Pavšič, J., Devonshire, A. S., Parkes, H., Schimmel, H., Foy, C. A., Karczmarczyk, M., et al. (2015). Standardization of nucleic acrid tests for clinical measurements of leaner and viruses. J. Clin. Microbiol. 53, 2008–2014. doi: 10.1128/JCM.02136-14
PubMed Abstract | CrossRef Total Text | Google Scholar
Pavšic, J., Žel, J., and Milavec, One thousand. (2016). Assessment of the existent-time PCR and different digital PCR platforms for DNA quantification. Anal. Bioanal. Chem. 408, 107–121. doi: 10.1007/s00216-015-9107-ii
PubMed Abstract | CrossRef Full Text | Google Scholar
Ricchi, Grand., Savi, R., Bolzoni, L., Pongolini, South., Grant, I. R., De Cicco, C., et al. (2016). Estimation of Mycobacterium avium subsp. paratuberculosis load in raw bulk tank milk in Emilia-Romagna Region (Italian republic) by qPCR. Microbiologyopen 5, 551–559. doi: x.1002/mbo3.350
PubMed Abstract | CrossRef Full Text | Google Scholar
Rijsman, Fifty. H., Monkelbaan, J. F., and Kusters, J. G. (2016). Clinical consequences of PCR based diagnosis of abdominal parasitic infections. J. Gastroenterol. Hepatol. 31, 1808–1815. doi: ten.1111/jgh.13412
PubMed Abstruse | CrossRef Full Text | Google Scholar
Rodriguez-Lazaro, D., Cook, N., and Hernandez, M. (2013). Real-time PCR in nutrient science: PCR diagnostics. Curr. Issues Mol. Biol. fifteen, 39–44.
PubMed Abstract | Google Scholar
Ruijter, J. Chiliad., Ramakers, C., Hoogaars, W. M., Karlen, Y., Bakker, O., van den Hoff, M. J., et al. (2009). Amplification efficiency: linking baseline and bias in the analysis of quantitative PCR data. Nucleic Acids Res. 37:e45. doi: 10.1093/nar/gkp045
PubMed Abstract | CrossRef Full Text | Google Scholar
Saiki, R. K., Gelfand, D. H., Stoffel, Southward., Scharf, S. J., Higuchi, R., Horn, G. T., et al. (1988). Primer-directed enzymatic distension of Deoxyribonucleic acid with a thermostable Dna polymerase. Science 239, 487–491.
PubMed Abstruse | Google Scholar
Saiki, R. K., Scharf, S., Faloona, F., Mullis, K. B., Horn, G. T., Erlich, H. A., et al. (1985). Enzymatic amplification of beta-globin genomic sequences and restriction site assay for diagnosis of sickle jail cell anemia. Science 230, 1350–1354.
PubMed Abstract | Google Scholar
Slana, I., Kralik, P., Kralova, A., and Pavlik, I. (2008). On-farm spread of Mycobacterium avium subsp. paratuberculosis in raw milk studied by IS900 and F57 competitive existent time quantitative PCR and culture examination. Int. J. Food Microbiol. 128, 250–257. doi: 10.1016/j.ijfoodmicro.2008.08.013
PubMed Abstruse | CrossRef Full Text | Google Scholar
Yang, S., and Rothman, R. E. (2004). PCR-based diagnostics for infectious diseases: uses, limitations, and futurity applications in acute-care settings. Lancet Infect. Dis. 4, 337–348. doi: 10.1016/S1473-3099(04)01044-8
PubMed Abstract | CrossRef Full Text | Google Scholar
Source: https://www.frontiersin.org/articles/10.3389/fmicb.2017.00108/full
0 Response to "Which Conclusion Can Be Made About a Sample When Using Only Pcr Technology to Detect Viruses?"
Post a Comment